The way your software helps you accomplish tasks with other software, that’s the human interface.
It would be both confusing and inappropriate to call the individual served by HI the user, and simply substituting human in the singular sounds too detached and frankly somewhat odd. Therefore, we adopt the placeholder name “Alice”.
The UI belongs to the end- or intermediate machine or service, and ultimately to the provider of that machine or service. The HI belongs to Alice. It supports many of the attributes scoped by attendees of the 22nd Internet Identity Workshop to describe sovereign technology and does not detract from the others.
Adaptation
An interface is humane if it is responsive to human needs and considerate of human frailties. If you want to create a humane interface, you must have an understanding of the relevant information on how both humans and machines operate.
Traditionally, the user is required to adapt to the UI. We all have different digital, numerical, information and visual literacy, and many people have one or more disabilities, yet UI/UX designers cannot cater to this variety.
Some interface concepts collect user information describing such differences and then customize the UI to better meet the user’s needs (CC/PP, ARIA and model-based UI). The product / service provider controls the type of user information collected and the bases by which that information is used to select from the options available, the variety of which may be dictated by cost-benefit analysis.
In contrast, HI adapts the data exchange, its presentation and the interaction with the machine or service to Alice’s needs. HI can aspire in the longer-term to be ‘just right’. Alice’s HI software exists to personalise her interface and will, subject to establishing a corresponding broad and deep ecosystem, be able to call on a massively more diverse set of components to achieve this goal, under her control.
HI not only adapts to Alice but with Alice. As Doc Searls of ProjectVRM and the Berkman Center for Internet & Society points out on our Champions page:
We’re all human. We’re also all now on one worldwide network, and we need to keep that human too. Nothing is more human than our differences — not only from each other, but from our former selves, even from moment to moment and context to context.
Decentralizing
The hi:project doesn’t require a eureka technology breakthrough, just the prodigious application of today’s Web standards and open tech. It’s been described as the democratization of the server.
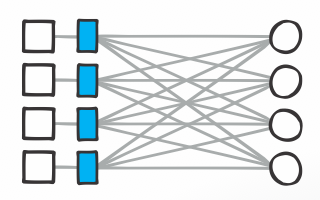
From the 90s – Organizations present websites and apps customers can interact with. There’s limited or zero facility to wield data or personalize the experience and users must like it or lump it. 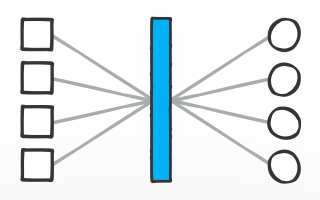
From the 00s – Third parties connect users to each other and organizations, centralizing and intermediating relationships. Their UI and policies do not correspond with ours here. As the saying goes, the users are the product. 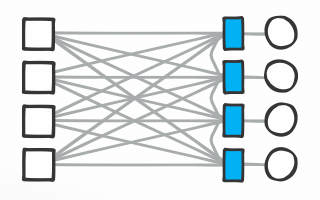
From the 10s – HI is simple and powerful, the interface that’s ‘perfectly yours’. The network is decentralized and relationships are disintermediated. Data / info spanning organizations can be visualized and understood.
The architecture
As Web of Data developments decouple the app from the data, the hi:project decouples the interface from the app. The hi:project re-imagines the interface as a lightweight artefact that can be shared within a community-based ecosystem. Participants are able to freely copy, modify and share improved or customised components, distributed and discoverable across a named data network architecture (or equivalent over IP) such as those proposed and developed by the Named Data Networking Consortium, MaidSAFE and IPFS, with provenance recorded in distributed ledger.
The following figure portrays the construction of Alice’s HI, and here’s an accompanying description.
Alice wishes to interact via / with a device or environment, hereafter just referred to as the device. The collection of devices / environments around the device she wishes to use represent a ‘fog’ (distributed around us) as opposed to today’s cloud (centralised ‘above us’).
The figure portrays eight steps.
- She authenticates with the identity she wishes to use.
- The device checks to see if it has the latest version of the hi:engine installed, and loads it accordingly. It loads Alice’s encrypted hi:profile, decrypting it with her private key. It also synchronises with Alice’s other concurrent HI sessions to get information about Alice’s current context and any tasks she is currently performing.
- On understanding the task Alice would like to perform, the hi:engine loads the relevant abstract HI – ie, an expression of the human interface that’s independent of the platform.
- The hi:engine refers to Alice’s hi:profile and checks the capabilities of the associated APIs from relevant service providers.
- With knowledge of the context, the device, Alice’s hi:profile and the API capabilities, the hi:engine calls on available hi:components to construct the concrete HI (modality dependent), and then the final HI (implementation and hi:profile dependent).
- The hi:engine manages data exchange with the relevant service providers. It may loop back to previous steps as needed.
- The hi:engine caches itself, Alice’s encrypted hi:profile, and the hi:components, reducing future latency and making the files more readily available to other devices. Alice’s hi:profile is updated based on the session.
- Alice de-authorises (logs out of) the device.
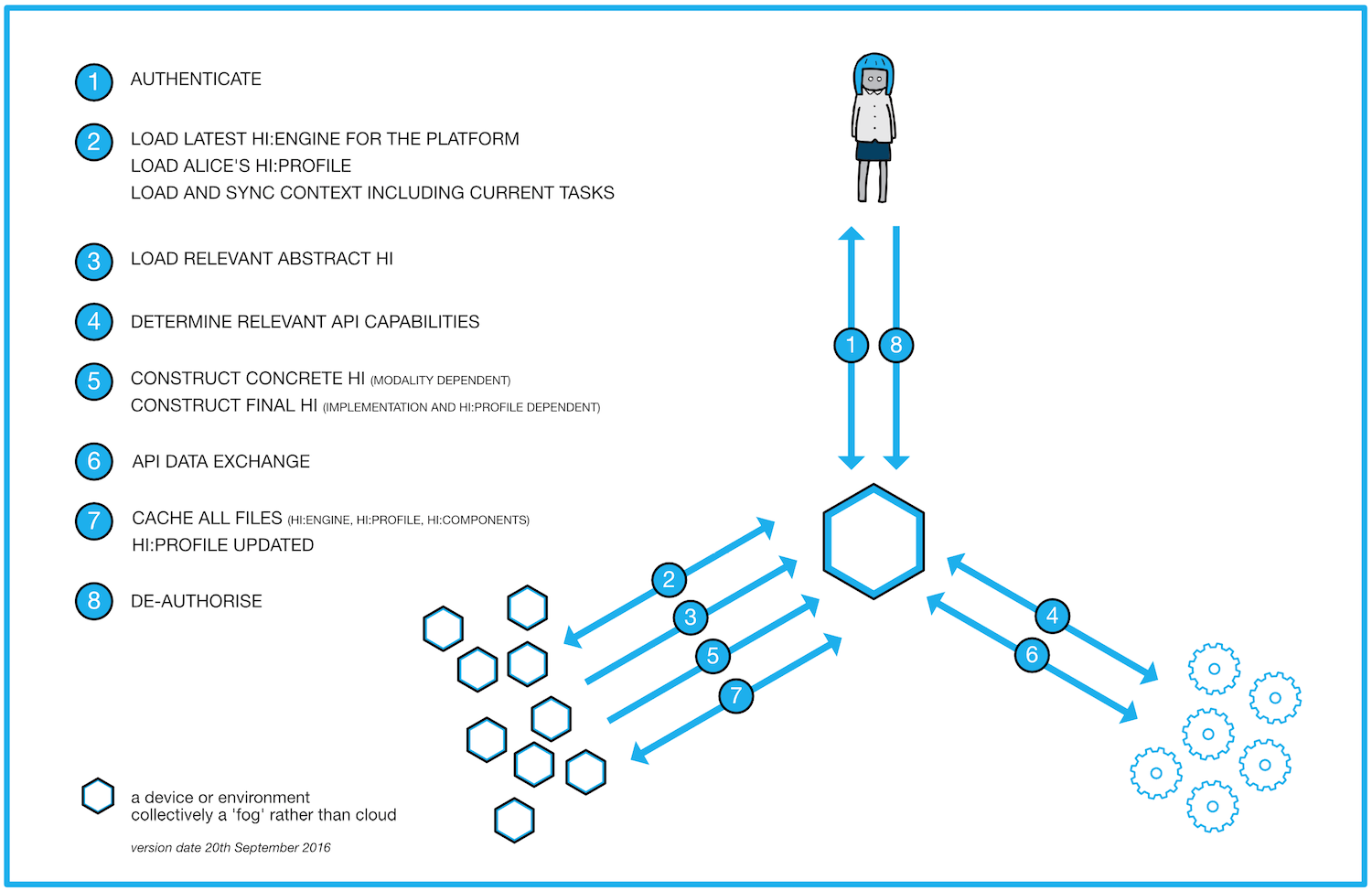 Constructing the HI
Constructing the HI
The engineering
The following sections outline the hi:framework, the hi:engine, the hi:profile, the hi:components, the hi:ontology, the hi:cache, and hi:coin. The project’s designs and technology are free and open source.
The hi:framework
The hi:framework details the hi:engine’s dynamics in terms of identifying service types, specifying APIs, determining how to personalize the HI, the collation and maintenance of the corresponding personalization data, and how this may then be wielded in selecting and assembling the hi:components available to it.
The hi:framework will be informed by existing model-based UI concepts – including abstract, concrete and final HI – and will address three levels of interface. Provider HI replaces a service provider’s UI. Service HI spans data describing Alice’s relationships with multiple service providers of the same ilk; a number of retail banks for example. The life facet HI enables Alice to review and interact with her life in the round, spanning services; her complete financial situation for example by combining data relating to banks, credit card issuers, mortgage providers, cryptocurrencies etc.
The framework will articulate a personal privacy profile to inform others how personal data should be treated in compliance with local regulations and personal preferences.
The hi:engine
The hi:engine is Alice’s personal software platform that assembles her personalised interface. (The way your software helps you accomplish tasks with other software, that’s the human interface.) It reads and writes to her hi:profile, calling the appropriate hi:components as needed contextually for Alice’s interaction purposes. It also maintains and communicates her privacy profile.
The hi:engine needs to learn from Alice, explicitly and implicitly. The simplest learning capability might be considered sufficient to render a HI experience superior to the UI equivalent, and such capability falls short of anything anyone might describe as artificial intelligence (AI). The hi:project does not aim to develop AI capabilities yet will explore the potential for integrating AI software and services developed by others to enhance the HI experience. The hi:project may, for example, be the ‘Open Interaction’ partner to OpenAI.
As and when service providers’ application programming interfaces (APIs) migrate to Linked Data format (and perhaps the hi:project might encourage such a transition), the hi:engine may act, less contextually, as a personal and personalised semantic web browser.
The hi:project does not aim to develop new approaches to personal identity and authentication; it is agnostic in this regard, enabling Alice to select her preferred approach(es) / service(s).
The hi:project is agnostic in terms of personal data stores. It will interoperate with such products and services, but stores are less relevant when personal data are available from source near instantly for personalised combination, presentation and interaction. Some storage facility may be pertinent with respect to data portability (changing service providers), and data backup will alleviate the disruption otherwise caused by the unexpected cessation of a service for whatever reason.
The hi:profile
Alice’s hi:profile informs the assembly of her HI in the moment. It is available and synchronised across platform / device / environment, and is subject to constant revision in terms of:
- Customization – the explicit statement of preferences (“I prefer …”)
- Crowd – learning from collective behaviours (“People who … prefer …”)
- Segmentation – identifying similarities between individuals (“People like you …”)
- Personal – implicit, interpreting the individual’s specific proclivities.
Pooling hi:profiles to enable such statistical analyses will be subject to the same privacy preserving techniques as for other personal data.
The hi:components
The materials the hi:engine works with: data and information models; graphical libraries; methods for adapting information appropriate to the topic, the individual, medium and context. The components will likely follow the model-based UI distinctions of abstract, concrete and final interface.
The hi:ontology
The hi:components and hi:profile will be described semantically, for optimal distribution and discovery in the case of the former.
The hi:cache
The cache of commonly used components, for reduced latency and for mesh / named data network availability.
The hi:coin
Depending on the parameters of the technology adoption model, a crypto-currency (hi:coin) may prove useful. Coin would flow from companies and other organized entities to Alice by way of payment for access to her HI, and from Alice to developers by way of design bounties, and from developers to companies by way of developer remuneration in fiat currency.
###