
It’s coming up to 15 years since Scientific American published “The Semantic Web: A new form of Web content that is meaningful to computers will unleash a revolution of new possibilities“, by Tim Berners-Lee, James Hendler, and Ora Lassila. (Paywall. Also available here.) I believe it’s the most cited paper on the subject.
The way the web works and is put to work changes, and in this post I explain how the hi:project relates to the Semantic Web, and then provide an introduction to the Semantic Web for those unfamiliar with it.
The Semantic Web and the hi:project
Three quotes from the paper ring out when we consider the hi:project’s mission. Undoubtedly, they informed the thinking that mashed up loads of other thinking into the hi:project.
The Semantic Web will bring structure to the meaningful content of Web pages, creating an environment where software agents roaming from page to page can readily carry out sophisticated tasks for users.
and
Traditional knowledge-representation systems typically have been centralized, requiring everyone to share exactly the same definition of common concepts such as “parent” or “vehicle.” But central control is stifling, and increasing the size and scope of such a system rapidly becomes unmanageable.
and
The real power of the Semantic Web will be realized when people create many programs that collect Web content from diverse sources, process the information and exchange the results with other programs.
If we’re going to do a bit of discourse analysis here, then the key concepts are:
- users – who else is this for but you and me?
- the decentralization of data / information / knowledge
- and helping data to breathe – an expression taken from the hi:project’s submission to the UN Data Revolution Group – so that data might find appropriate context to become information, accessible and useful ultimately to … yes … you and me.
If the most familiar form of the Web is a web of documents, then the Semantic Web is a web of data.
The paper asserts that the Semantic Web is not a separate web but an extension of the current one. However, the Web of documents has changed substantially since the paper was published. It’s now subject to mass surveillance by governments and marketing technologists. It’s largely mediated by the likes of Google, Apple and Facebook. The user is the product (ie, the thing that’s monetized). And such mediation has centralized the flows of data and information, and in proprietary and/or closed manner as and when this is pertinent to a given business model.
It remains valid to have hyperdata accompany hypertext. The reciprocal matters less.
(Frustratingly, less than optimal accessibility and digital inclusion remain constants.)
In my opinion, to be human-centric (rather than business-centric, or business-centric labelled ‘user-centric’), to be decentralizing, to enhance individual agency in the way the paper describes, the Semantic Web viewed through a 2016 rather than 2001 lens could benefit greatly from what we call the human interface. While they are independent of each other, they are mutually supportive.
HI works just fine with APIs in general – and indeed that’s how it’s envisaged to support a realistic adoption path – but it becomes a personal and personalised semantic web browser when such APIs expose data semantically. Moreover, the hi:components (the models, libraries and methods required by a human interface) may well be described semantically themselves for optimal distributed discovery and application.
A brief introduction to the Semantic Web
What do you think of Berlin?
You have no problem with that question. Your amazing mind has already placed it in a context that works for you. You may not therefore appreciate how much your mind has done on autopilot, or indeed how complex the question is devoid of context.
So what is your context?
If you’re into great 20th Century songwriting, you may be thinking about the works of Irving Berlin.

Perhaps you’re a New Wave fan and you’re contemplating the American synth pop band most famous for “Take My Breath Away”. Maybe your appetite for popular culture reached its zenith in the 70s, in which case Bowie’s Berlin Trilogy is front of mind, or Lou Reed’s Berlin album, either because it was regarded by Rolling Stone magazine as “a disaster”, or because it still made Rolling Stone’s Top 500 albums of all time. Go figure.
Perhaps you’re thinking in terms of place not music, in which case it’s obvious right?

Well, the capital of Germany goes by the name of course, but so do around twenty places in the US and one in South Africa.
So if you were to express an opinion or publish anything about Berlin in a digital format, a format that can be read and machined by, well, machines, then the utility of that machining would be greatly enhanced if it could determine which entity called Berlin you’re actually talking about.
This is the domain of the Semantic Web.
Retrospectively, the initial manifestation of the web, a web of interlinked documents, is often referred to as Web 1.0. The social web, Web 2.0, is a web of people – or at least a web of documents representing people.
The Semantic Web (Web 3.0?) is about the Web itself understanding the meaning of the content and social participation. In the words of Sir Tim Berners-Lee, inventor of the World Wide Web, the Web becomes a universal medium for the exchange of data, information and knowledge.
The Semantic Web is a collaborative movement led by the international standards body, the World Wide Web Consortium (W3C).
Disambiguation

So, I want to be really clear about what I mean when I write “I love Berlin”. We’ve already seen how that simple phrase is ambiguous without additional clarification.
Which Berlin?
As we’ll see, the Semantic Web allows data to be described with reference to universally available common vocabularies. I need to reference one of those universal vocabularies to declare which Berlin I’m talking about. In the jargon, I’m disambiguating.
I’m talking about the capital of Germany, and the particular vocabulary I need in this instance is the one for geographic names called GeoNames.
A vocabulary is structured with Unique Resource Identifiers, or URIs for short. A URL, Unique Resource Locator, is a type of URI.
Now here’s a subtle but important distinction. A webpage about Berlin is not Berlin. Obviously. So there are two URIs relating to Berlin here:
http://www.geonames.org/2950159/berlin.html – this URI stands for Berlin. We use this URI when we want to refer to the city of Berlin, Germany.

http://www.geonames.org/2950159/about.html – this URI is the document with the information GeoNames has about Berlin, Germany.
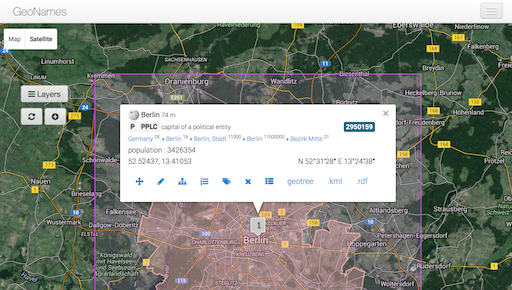
There is an expectation however that a web browser should be able to resolve the first URI – in other words, show you some information about Berlin rather than show you around Berlin itself! So for this reason, GeoNames redirects any web browser calling for the first URI to the content available at the second URI.
The webpage describing the ‘resource’ called Berlin is a street map or satellite image of the area featuring:
- the latitude, longitude and altitude
- the population
- a link that calls up a list of alternate names and name variants (Berliini in Finnish, Berlijn in Dutch)
- a link to a ‘geotree’ listing the geographies that make up the place in question and the wider geography in which it’s located
- And the hyperlinked text “.rdf”.
RDF
RDF stands for resource description framework, a metadata data model. In plainer English, RDF is a family of standard ways to present data about entities – Berlin in our example. The RDF link for Berlin is:
http://www.geonames.org/2950159/about.rdf
Follow that link and take a look. It’s not as fearsome as it might first appear, but you can see why this stuff is usually the preserve of machines rather than humans.
Now, I’m sure you’ll agree, there’s no confusing the object of my affection. This obviously isn’t the Town of Berlin, Worcester County, Massachusetts. You’ll find that’s: http://www.geonames.org/4930436/town-of-berlin.html
Or the ghost town in Nevada: http://www.geonames.org/5499945/berlin.html

And I’m obviously not referring to Irving, as much as I might like “Puttin’ on the Ritz”. You can find a RDF document for him here: http://dbpedia.org/data/Irving_Berlin.rdf
Linked Data
The Semantic Web includes a vision known as Linked Data. In simple terms it builds on HTML, RDF and URIs to interlink published structured data to make it more useful, more valuable.
Sir Tim Berners-Lee has outlined four principles of the Linked Data approach, effectively:
- Use URIs to identify things
- Use HTTP URIs so that these things can be referred to and looked up (“dereferenced”) by people or software acting on someone’s behalf
- Provide useful information about the thing when its URI is dereferenced, using standard formats such as RDF/XML
- Include links to other, related URIs in the exposed data to improve discovery of other related information on the Web.
This website maintains a map of the Linked Open Data web from time to time (as of August 2014 at the time of writing).
Bottom-up
This bottom-up approach demands diligent markup of web content, and for this reason many consider it to be laborious, long-term work. Nevertheless, the BBC is a leading exponent (its brilliant London 2012 Olympics website is semantically powered), the UK government leads the world with the data.gov.uk facility, and a project called dbpedia endeavours to semantically markup the entire Wikipedia corpus (you may have noticed dbpedia in the link to Irving Berlin’s RDF).
I should add that while publishing semantically marked up content requires a bit more effort, you don’t need to create RDF directly. Appropriately capable content management systems should look after that for you.
Knowledge Graph / Top-down
Commercial imperative drives innovations to link things together sooner than a bottom-up only way might otherwise achieve, and perhaps it’s no surprise that Google leads the way here. Here’s what the Google blog had to say about the May 2012 launch of its Knowledge Graph:
Search is a lot about discovery – the basic human need to learn and broaden your horizons. But searching still requires a lot of hard work by you, the user … Take a query like [taj mahal]. For more than four decades, search has essentially been about matching keywords to queries. To a search engine the words [taj mahal] have been just that – two words.
But we all know that [taj mahal] has a much richer meaning. You might think of one of the world’s most beautiful monuments, or a Grammy Award-winning musician, or possibly even a casino in Atlantic City, NJ. Or, depending on when you last ate, the nearest Indian restaurant. It’s why we’ve been working on an intelligent model – in geek-speak, a ‘graph’ – that understands real-world entities and their relationships to one another: things, not strings.
How does Google attempt this? Well first and foremost it taps into the bottom-up work achieved so far with those public Linked Data datasets, and they’re augmenting this with some smart software designed to determine the precise entity described in web content even when it isn’t semantically marked up – what you might call a top-down approach.
According to a December 2012 post to Google’s Search Blog, the Knowledge Graph covered 580 million objects (entities) and 18 billion facts and connections at that time.
Fundamentally, Google is intent on “building the next generation of search, which taps into the collective intelligence of the web and understands the world a bit more like people do”, which sounds very similar to the intent for the Semantic Web.
If you use Google search then you will have seen some immediate manifestations of this work.
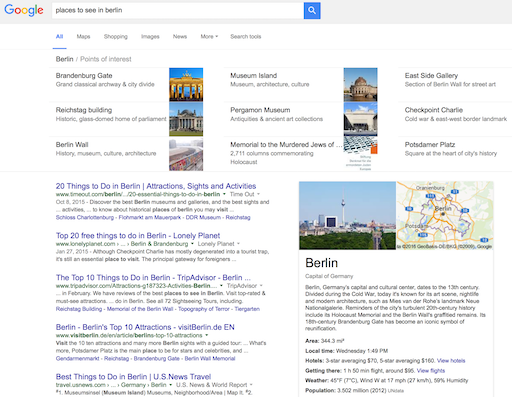
As of mid-2012, typing a famous person’s name into Google search for example usually brings up a collection of images and information to the right of the main search results about that individual.
Enter “Berlin” and you’ll see things like a map of the German capital, a description of the city, the population, the weather, the local time, etc. That is if Google’s algorithms determine you’re looking for information about the German capital of course rather than another entity of the same name.
As of mid-2013, Google also introduced the Knowledge Graph powered image carousel above the main search results.
Absent disambiguation, the Knowledge Graph craves context. Take a search for “Soho” for example. As a London resident writing this in London and employing my default browser Firefox, Google Search presents me with Knowledge Graph information about Soho in London. However, if I boot up a different browser and tell Google to ignore my location (by going to www.google.com/ncr), I get information about Soho in New York.
Link it together

Now, if you specify a date you’re going to be in Berlin, and it happens to coincide with my next stay in Berlin, we can rest assured it’s the same place and we can get together for a Berliner Weisse.
In fact, if we describe our friendship semantically, and if we describe our predilection for German beer semantically, then our respective semantic calendar services might auto-suggest our getting together at a specific time and place without our having to labour over it.
And perhaps a mutual friend has expressed their love of a suitable venue via a service making it semantically understandable. But that’s a fairly trivial example.
At the other end of the spectrum, imagine that all the data harvested by cancer research scientists around the world is published semantically. This allows a semantic data scientist to study the studies, merging datasets and finding patterns and reaching conclusions that would otherwise have proved very difficult or impossible.

Imagine a ‘semantic data Member of Parliament’, a ‘semantic data town planner’, a ‘semantic data journalist’.
Imagine a ‘semantic data you’.
One thought on “Fifteen years since the Scientific American article on the Semantic Web”
Comments are closed.